Task History
- DarkLight
Task History
- DarkLight
Article Summary
Share feedback
Thanks for sharing your feedback!
Overview
Task History allows users to look through every job run the instance has performed within the scope of the current Project. Tasks can be seen as a discrete unit of work. A job run begins a task, as do the components within that run. Users can access detailed information on job runs, their tasks and the status of those tasks.
Task information is accessed by clicking Project → Task History. This allows you to view the information in the user interface, but to perform any kind of diagnosis or analysis of the jobs that have been run, it is useful to take this task information and load it into a table for further processing.
You can use the Matillion API to return task information as a JSON string. This JSON string is not easy to view and interpret, particularly if it includes a large number of jobs, but if you use the API Query component you can take the JSON and reformat it into a table. This article explains this process.
Note
- You must authenticate as a user with API privileges if you wish to work with the Matillion API.
- This article uses the "v1" version of the Matillion API. For more information on using this API, read Matillion ETL API - v1.
Task History
To access Task History in Matillion ETL, click Project → Task History.
Completed runs will be listed with the below details:
- Job Type: A symbol denoting an Orchestration task run (blue) or Transformation task run (green).
- ID: The ID of the task run. This can be referenced when using the Matillion ETL API.
- Task Type: How the task was executed. Run for if a component was run, Run Job for if an entire job was run, Schedule for if a job was run by the scheduler.
- Version: The Project version the job existed in when this task was executed.
- Job: The name of the job this task belonged to.
- Environment: The environment used for this task run.
- Queued: The timestamp for when this task was queued.
- Started: The timestamp for when this task was executed.
- Ended: The timestamp for when this task completed (successfully or otherwise).
- Duration: The duration of this task run.
- Detailed View: Click to see a tree structure for the task and all subtasks in this entry.
- Historic Jobs: Click to see how this job was configured at the time of running. See the Historic Jobs section for more information.
- End Status: A symbol denoting how this task ended. Either Success (green) or Failure (red).
The task history may have multiple pages of results that can be scrolled through at the bottom of the dialog.
Historic Jobs
Historic Jobs allows users to view how a job was set up at the time of running via the Task History dialog. The task history records each job exactly as it was when the job was running, including the job's layout, notes, and component properties and configurations.
- In Matillion ETL, click Project → Task History. This will open the Task History tab, which lists previously run tasks.
- In the Task History list, click the tape icon next to a task to see the Historic Jobs panel with job details for that task.

- In the Historic Jobs panel for your selected task, under the Job Name heading, click the name of the job you wish to view. The job's canvas will be displayed to the right.

Note
When a shared job is run as part of a task, the jobs bundled into the shared job are given the prefix Shared job followed by <PackageName>,<SharedJobName> in the Historic Jobs view.
Clicking on a job in the Historic Jobs tree will show the canvas for how that job existed at the time of its execution in the Task History. Selecting components on the canvas will reveal their properties configuration at that point in time.
The component properties can also be selected to reveal their full information, but they cannot be altered.
Using the Task API
The Task API can be used to return task information as a JSON string. You can retrieve either the task history or a list of tasks currently running.
To retrieve currently running tasks, the format of the API call is:
curl -X GET "http://<InstanceAddress>/rest/v1/group/name/<groupName>/project/name/<projectName>/task/running"
To retrieve the task history, the format of the API call is:
curl -X GET "http://<InstanceAddress>/rest/v1/group/name/<groupName>/project/name/<projectName>/task/history?since=<since>"
The since parameter allows you to specify the start of the time period you want to retrieve task information from, and has the form yyyy-MM-dd.
For example:
curl -X GET "http://your.server.com/rest/v1/group/name/MainGroup/project/name/BookKeeping/task/history?since=2022-10-31"
The result in this example is a JSON string that gives information on historical tasks from October 31, 2022 to the current date, from the project group called "MainGroup" and the project called "BookKeeping".
These API calls will return a task list in the form of JSON data, but don't create a file or import the information into a table. To do this, you can instead make use of Matillion ETL's API Query component, as described in the following section.
Using the API Query component
To put the task information into a more useable format, create an orchestration job that uses an API Query component. In the following example, we use the API Query component to extract Matillion ETL task information which is then passed to a transformation job to filter out any failed jobs, convert the dates into a more readable format, and finally save the remaining entries into table that will be stored on an S3 Bucket.
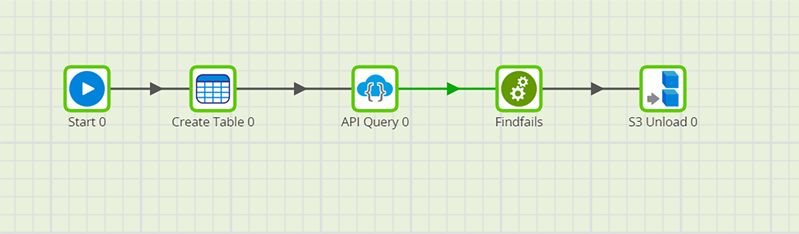
The transformation job "Findfails" in this example is created as follows:
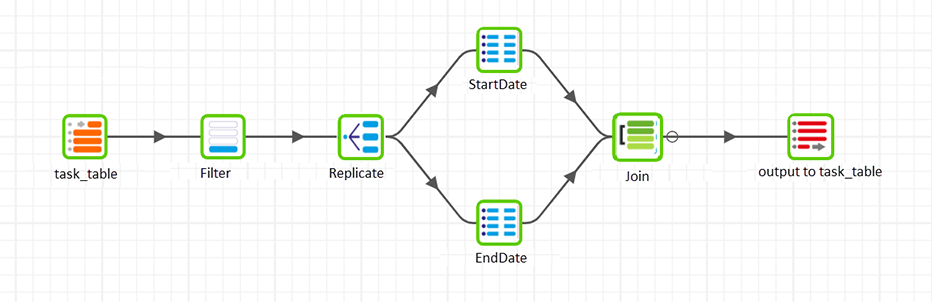
The components used in these jobs are described below.
Create Table
The orchestration job begins with a Create Table component that creates a table called "task_table", which the job will write the task history to.
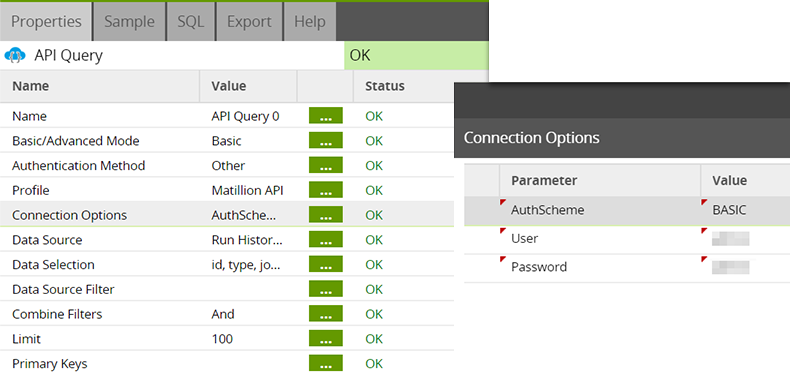
API Query
The API Query component is configured to use the Matillion API, with the data source specified as "Run History Details".
You can find the "Run History Details" API profile through Project → Manage API Profiles → Manage Query Profiles. Select Matillion API and then Run History Details.rsd:
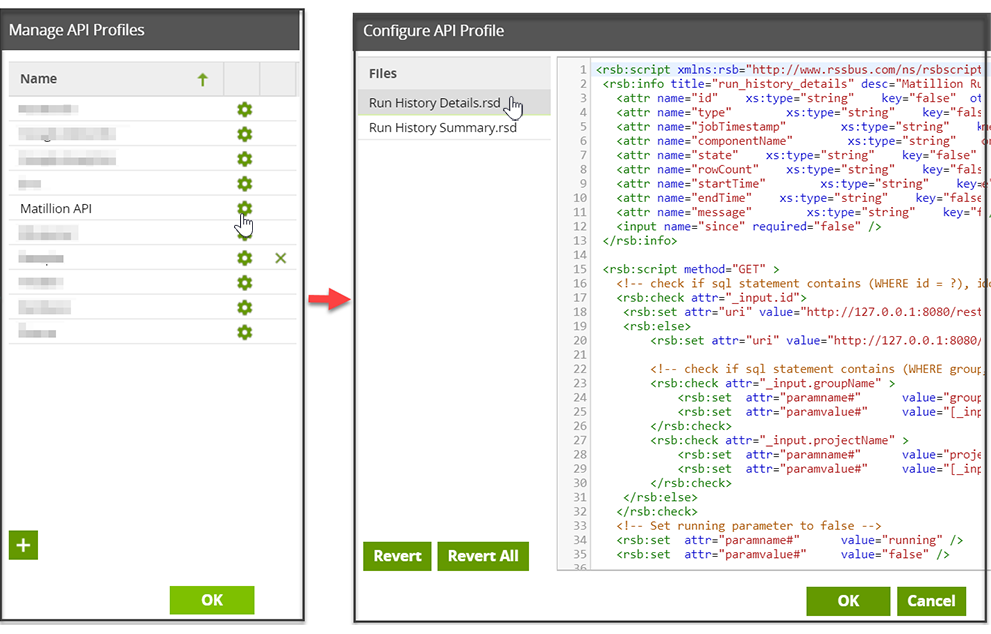
To provide the "AuthScheme", "User", and "Password" needed for the Matillion API call, add the following entries to the Connection Options property of the API Query component:
AuthScheme = BASICUser = <your Matillion ETL instance username>Password = <your Matillion ETL instance password>
Note
For versions of Matillion ETL when the REST driver was updated from the 2016 driver to the 2019 driver, you may encounter issues where data is not being flattened or is displaying as a single row rather than multiple values. To fix this, add the following entry to the Connection Options property:
BackwardscompatibilityMode = true
The API query component in this example uses an API call like this one to retrieve the task history:
http://your.server.com/rest/v1/group/name/MainGroup/project/name/BookKeeping/task/history?since=2022-10-31
This returns the task history in JSON format, such as this:
{
"id": 63018,
"type": "RUN_ORCHESTRATION",
"customerID": 793,
"groupName": "MainGroup",
"projectID": 795,
"projectName": "BookKeeping",
"versionID": 796,
"versionName": "default",
"jobID": 827,
"jobName": "Sleep",
"environmentID": 799,
"environmentName": "test",
"state": "SUCCESS",
"enqueuedTime": 1594729190954,
"startTime": 1594729190955,
"endTime": 1594729201024,
"message": null,
"originatorID": "ws_61498_7",
"rowCount": 0,
"tasks": [
{
"taskID": 1,
"parentID": -1,
"type": "VALIDATE_ORCHESTRATION",
"jobID": 827,
"jobName": "Sleep",
"jobRevision": 2,
"jobTimestamp": 1594714500345,
"componentID": 828,
"componentName": "Start 0",
"state": "SUCCESS",
"rowCount": -1,
"startTime": 1594729190956,
"endTime": 1594729190958,
"message": ""
},
{
"taskID": 2,...
}
],
"hasHistoricJobs": true,
"jobNames": [
"API JOB TEST"
]
}
The API Query component stores the job data in a table that the "Findfails" transformation job can use. In the transformation job, the data is filtered to take only successful runs, and then has two SQL components that reformat the start and end times. Finally, these data streams are joined and columns are selected to output to a table.
Table Input
In the transformation job, "task_table" is a Table Input component that contains the returned table from the API Query component, in other words the task data that has been taken from the JSON string that the Matillion API returns.
Filter
In our example several jobs have failed, and for our report we only want to show the successful runs. To remove the failed rows we add a Filter component, configured to filter out any rows where the state column is not equal to SUCCESS.
Replicate
We want to change the dates from the JSON output into a readable format. We can do this with SQL commands, but as there are two different dates to manipulate, startdate and enddate, we will need to use two different SQL components. The Replicate component splits the filtered data into two different streams, each one going to a different SQL component. We will re-join the two streams after the SQL processing is complete.
SQL
Now we can use the two SQL components to change the dates to a readable format. The required commands are platform dependent, as follows.
- Snowflake:
SELECT DATEADD(MS, "starttime", 0::TIMESTAMP) as startdate ,* FROM task_table;
SELECT DATEADD(MS, "endtime", 0::TIMESTAMP) as enddate ,* FROM task_table;
- Amazon Redshift and Google BigQuery:
SELECT TIMESTAMP 'epoch' + convert(bigint, starttime/1000) * INTERVAL '1 Second ' as startdate ,* FROM task_table
SELECT TIMESTAMP 'epoch' + convert(bigint, endtime/1000) * INTERVAL '1 Second ' as enddate ,* FROM task_table
Join
The Join component is used to take the data output from these SQL components (termed A and B in the Join component) and return a single table.
The two tables (A and B) are compared. We use the "id" and "componentname" columns to ensure rows from A and B are the same, so we can take the "enddate" from B and match to the correct row in A. At this stage, we can also omit any columns that are unwanted.
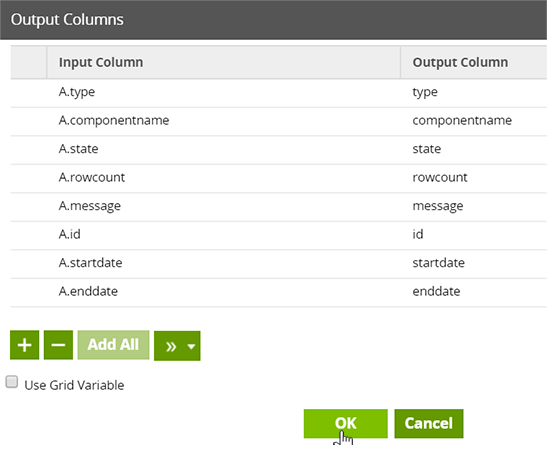
Table Output
This data is then written to "task_table" using the Table Output component, which we have called "output to task_table" on the job canvas for clarity.
The data can be checked using the Sample tab of either the Join or Table Output components to confirm that the transformation has worked as expected, the "starttime" and "endtime" are reformatted correctly, and the desired columns are present.
S3 Unload
This data will remain in "task_table", which will be written to an S3 bucket by the S3 Unload component in the orchestration job.