Parallelism with Matillion ETL for Redshift
- DarkLight
Parallelism with Matillion ETL for Redshift
- DarkLight
Article Summary
Share feedback
Thanks for sharing your feedback!
Overview
While developing Orchestration jobs with Matillion ETL, you may have noticed that Transformation jobs which are able to run in parallel actually run serially: one after the other.
Similarly, when developing a Transformation job with multiple “Write” components, you may have noticed that only one of them actually runs at a time.
Many Data Warehouses support multiple simultaneous database connections, and each of those can be simultaneously running SQL. Thus, the single-threading limitation must be coming from Matillion ETL. In this article, the practical effects of parallel jobs are explored.
Amazon Redshift is used as the example Data Warehouse, but the lessons on parallel job design are common regardless of your Data Warehouse choice.
MPP architecture
In Amazon's own words, Redshift delivers fast query performance by parallelising queries across multiple nodes.
This means that while a query is running, all the nodes in the cluster are contributing.

Furthermore, it's ideal if all the nodes are contributing equally while a query is running. It would be a pity if one of the compute nodes had to do far more work to than the others: most of the cluster resources would be idle while one of the nodes was working at full capacity. Avoiding this situation is one of the goals of a good row distribution style.
Matillion ETL Transformation jobs run pushdown SQL, and they take advantage of Redshift's ability to parallelize the execution. This is one factor which helps Matillion ETL achieve great performance. So let's look in detail at how Matillion ETL's jobs operate on Redshift's MPP architecture.
Transformation Job
In this Transformation job, two independent Rewrite Table components are taken from a single source, via a Replicate component. The two Rewrite Table components are identical apart from their Target Table Name.

Logically there's no reason why the two CTAS statements shouldn't run at the same time. In fact, when you launch this job, the Matillion ETL Tasks window does show both components in RUNNING state.
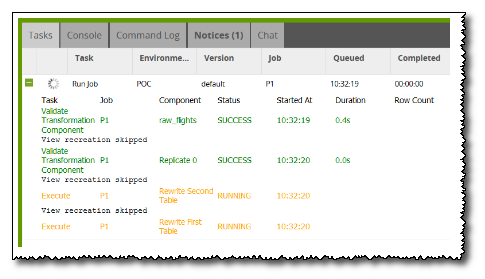
But the Redshift Performance console tells a different story. You can see that the two SQL statements actually run serially. The second one starts as soon as the first one finishes, while the CPU usage is almost constantly at 100% throughout.

Once the job has completed, check the Matillion ETL Tasks window again to review the timings.

The second of the Rewrite Table components didn't actually start running until the first one had finished, so it took almost exactly twice as long to change from “ready” to “finished”.
In order to find why Matillion ETL Transformation jobs behave this way, we need to take a look at how Redshift performs when the two SQL statements are forced to run in parallel. This is possible using Matillion ETL Orchestration jobs.
Orchestration Jobs
To force two SQL statements to run in parallel, you can create two Orchestration jobs, both of which runs a single Transformation job, and schedule them to start at the same time.
The two Transformation jobs in this case run the same two Rewrite Table tasks that we were using in the previous example.

The next screen capture shows the Redshift Performance console during a series of three runs, on an otherwise-idle Redshift cluster:
- From 10:41 - 10:46 - one Rewrite Table (A) running on its own.
- From 10:53 - 11:02 - both Rewrite Table statements (A and B) running at the same time.
- From 11:05 - 11:13 - the two Rewrite Table statements running one after the other (A followed by B)

With the CPU state and timings added, the observations are:
- Whenever Query A or B run on their own, they each take slightly over 4 minutes.
- When Query A and B run in parallel, they each take twice as long.

The reason for this is that when either query A or query B run on their own, all the nodes in the cluster will run at full capacity to satisfy the query. As mentioned at the beginning of the document, this is one of the goals of a good row distribution style.
So, when query A and B are forced to run in parallel, they compete with each other for resources, and both end up taking twice as long.
Conclusion
Matillion ETL for Redshift does introduce a restriction of only allowing one piece of Transformation pushdown SQL to run at a time.
But this restriction is a deliberate design feature. Due to Redshift's MPP architecture, every single pushdown SQL statement is already running in parallel, even when it's the only SQL statement running on the cluster. The design goal is for every node to be running at full capacity and performing an equal share of the work. You can see this in the fact that the CPU is running at 100% in the first and third of the above experimental runs, while queries A and B are running on their own.
Running a second query while another is already running does not result in a performance gain. In the second of the experimental runs above, while queries A and B are running at the same time, the CPU usage is still at 100%, and both queries simply take twice as long since they only have access to half the resources.
This illustrates one of Redshift's core design principles: if you don't scale the cluster yourself, the price is constant, and therefore so are the system's resources.
One final point on the Matillion ETL design: an addition benefit of having only one database connection to Redshift is that Matillion ETL is able to offer transaction control statements (commit and rollback). This gives you extra design options for re-runnability and re-startability in the Orchestration jobs that you build.